
Machine learning and AI have seen a lot of attention in the media. What can it do? How will it affect our future in software testing?
All these are exciting questions. But most people view machine learning as this magic black box.
A thing that can “learn” a problem and then perform a task. And is this now AI? Is AI and machine learning the same thing?
These questions, what AI and machine learning are and what they can do, become clearer when we have a high-level overview of how it all works. This is what we are doing in this article, giving you an overview of what AI and machine learning are, how it works, and the way it is currently evolving, and where the boundaries are.
Machine Learning vs. AI: Is it a bird, or is it a plane?
So, what is the difference between AI and machine learning? Many people use it as a synonym. Depending on the context, it is not wrong, just maybe inaccurate.
Per definition, Artificial intelligence (AI) refers to developing computer systems and algorithms capable of simulating or supporting human-like cognitive abilities such as learning, reasoning, problem-solving, and automated decision-making.
Machine learning is a field of artificial intelligence that focuses on developing algorithms and models that allow computers to learn from data and automatically recognize patterns to make predictions or decisions without explicit programming.
So, let us start with the context. The difference becomes clear when we look at AI and machine learning applied to a concrete example problem:

Source: https://www.aphis.usda.gov
There is a bird wildlife resort close to the airport. We want to ensure the bird population is healthy and measure the effect of airplanes flying over the resort.
So, we want to count the area's birds and planes. We can achieve this by putting a human in the middle of the resort, who is tasked to count planes and birds for hours, or using a camera that does the same.
We call the whole system, the camera which counts birds or planes, an AI system.
It automates the task of counting birds and planes in the wildlife resort. Typically, this task consists of several sub-tasks like detecting moving objects, classifying them as birds or planes, and counting them in a central database.
Machine Learning can be part of an AI system, but it does not have to be. Indeed, we can build an AI system without machine learning.
Detecting moving objects can be done by using video processing software. We can then classify the moving objects according to their size in the video feed: A large object is likely an airplane, and a small object is likely a bird. We can invent and implement these rules "by hand". With a programming language of our choice, or even in Excel: "If an object is larger than 50 pixels, it is classified as a Plane." This is a classifier that does not use machine learning but uses "handcrafted" features.
However, this AI system, which does not use machine learning, probably does not perform very well.
If a bird flies closely over the camera, the system detects it as an airplane. Similarly, smaller airplanes that fly higher up may be classified as birds. This is an issue because the classification of bird/plane is the central decision point in our AI system. We need an accurate classification for the whole system to be helpful.
Thus, we already have a video feed of the moving objects. Could we improve the bird/plane classifier by using the video feed directly?
Indeed, we can, with machine learning!
We can use machine learning to classify moving objects as either birds or planes by interpreting the image of the objects instead of some abstraction.
In an AI system, we typically use machine learning for the central sub-task, like classifying birds and planes in this example. Machine learning models often tend to be used at the core of the AI system.
Let us look at how a typical machine learning model classifies birds/planes, to what extent it can make the distinctions, and in what cases it has pitfalls.
A machine-learning bird/plane classifier
In our system, we detect a moving object and want to classify it as either a bird or a plane.
As an input, it gets the image of the moving object. From the image, it calculates two numbers: How sure the machine is the image contains a bird, and how sure the machine is the image contains a plane.
We call them "is a bird" and "is a plane" from here on out. The higher number is the detected class of the image.
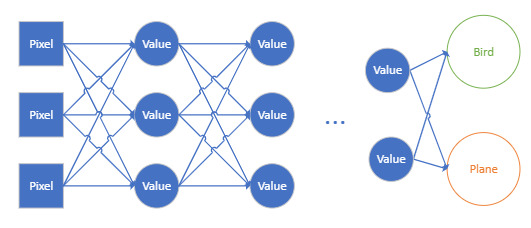
Figure 1: Example of how a machine calculates the two answers. Notice how it looks like a network of sorts.
So far, so good, but how does a machine learning classifier arrive at the numbers "is a bird" and "is a plane"?
The answer may be a bit irritating. It... calculates them.
Figure 1 shows how the machine starts at pixels of the image and feeds them through a network-like structure (like, a neural network? Hint-Hint). We start at the image's pixel values and have layer after layer of intermediate nodes. Then, in the end, we have the two output nodes, which represent the two numbers "is a bird" and "is a plane." The connections between the nodes say, "Take the value of the current node, multiply it by a factor, and pass it along."
Let us look at the first intermediate value in the network. It has three connections in the diagram. Each connects it to a pixel. The intermediate value is then calculated by:
- Take the value of Pixel 1, multiply by the first multiplication factor
- Take the value of Pixel 2, multiply by the second multiplication factor
- Take the value of Pixel 3, multiply by the third multiplication factor
- Add these three numbers together, and presto!
One detail is left out here for simplicity: Each intermediate value does not simply get passed along in the network but is fed into a non-linear function like a sigmoid before it is passed on. It is necessary for complex math reasons. We leave the discussion out because it is simpler to explain and is still correct. You can technically create a linear network, but a real-world network typically uses a non-linear function.
When we say: "The machine has learned to classify images as birds or planes." All that this entails is we have found all multiplication factors in the network necessary to calculate the "Is a bird" and "Is a plane" numbers.
Our bird/plane classifier machine relies on a bunch of multiplication factors to calculate its two output numbers, "is a bird" and "is a plane". The issue is that nobody knows the multiplication factor that this machine needs.
Luckily, there is a way to find the factors.
We can feed the machine examples. Images, for which we know whether it is a bird or a plane. Then, we let the machine find its multiplication factors.
In essence, we let the machine "learn" its multiplication factors from the data. Of course, this is not trivial in practice (read: More fancy math notations containing most of the Greek alphabet). But the working principle is surprisingly intuitive. Indeed, we have used a similar principle for centuries. For example: Artillery cannons!
In the age of Napoleon Bonaparte, artillery cannons were an important part of any battle. But actually, hitting the target is hard. The range of the gun is influenced by everything. The weather, if the gun is set up on higher ground than the target, the amount of black powder used, and, of course, the actual distance to the target. Most of these variables were hard to measure at the time. So, calculating the correct setup was out of the question. What the artillery officers did was "walking in the artillery"; They simply fired at the target, and watched where it landed. Did it overshoot the target? Then, reduce the amount of black powder and try again. Shot for shot, the artillery was walked in on the target until they could hit it.
Learning the multiplication factors for our bird/plane classifier machine works similarly. We start with random multiplication factors and feed them with images of birds and planes. Now, we use fancy math equations to find out how far off we are from the target and what multiplication factors we must correct to get closer. We modify the multiplication factors and repeat. Bit by bit, our bird/plane classifier machine walks in on the target until it produces large "is a bird" values when the image contains a bird and large "is a plane" values when it contains a plane.
This is the working principles principle of how machine learning works. We use a bunch of training data and let the machine change its multiplication factors until it hits the target. When the machine can hit its target reliably, it is common in common parlance to say: "The machine has learned the bird/plane classification task."
Learning has a lot of connotations in our mind that hold true for humans but may not be true for machine learning.
For example, what happens when we feed our bird/plane classifier an image of a drone? Since our machine has learned the bird/plane classification task, we might expect it to say it is neither bird nor plane (both "is a bird" and "is a plane" numbers are close to zero).
But in reality, this may not be the case.
It may confidently say, "It is a bird", or "It is surely a plane", or it might say it is both (both "is a bird" and "is a plane" are high). There is no easy way of telling what the machine might do when we feed it with an image of a new type of object.
But what did the machine learn? What can we expect from it?
Here, we dip our toes into active machine-learning research. What has our bird/plane classifier machine learned? How does it behave in edge cases, like when it sees a drone?
All these questions currently cannot be answered in general. Even in a specific case where one analyses a concrete machine with a fixed set of multiplication factors, the answers may be complicated and unsatisfying.
Luckily, there is again a simpler intuition behind what a machine has learned, which can tell you at least why these questions are complicated.
All a machine can learn is correlations!
Our bird/plane classifier machine calculates the "is a bird" and " is a plane" numbers from the pixel values of an image. In essence, it has found how the pixels correlate with the " is a bird" and " is a plane" numbers. These correlations may be simple; for example, the bottom-left pixel's color correlates with birds if it is green, or with planes if it is blueish grey.
It might have found complex correlations; for example, if the wingtips are split into multiple tips, it correlates with birds. Our bird/plane classifier machine consists of a bunch of correlations. Some may be the result of bias in our training images, like the correlation with a specific pixel color, and some may work well in actual use. All these correlations are encoded in the multiplication factors.
If we want to predict how our bird/plane classifier acts in edge cases, we have to analyze what correlations are encoded in the multiplication factors. Then, we can extrapolate how they might interact on an image of a drone. What correlations a machine will learn depends in large part on the data it has seen during training. If we train our bird/plane classifier machine on a completely different set of bird/plane images, it will find a different set of correlations.
Describing machine learning as a set of correlations might be discouraging for some. The sentence "correlation does not mean causation" is repeated in every statistics class.
If we can only find correlations with machine learning, is machine learning even useful?
Well, yes! Remember the non-machine learning bird/plane classifier in the beginning: Instead of looking at pixels, we compare the size of the moving object. Small objects are birds; big objects are planes. This, too, is a correlation. The size of the object correlates with it, either being a bird or a plane. But it is a correlation that we designed, that we know, and can think about its implications.
Machine learning: A conversation about Data
In any AI system, there is a part that is responsible for a central decision. In our example, we want to keep an eye on a wildlife resort close to an airport. The central decision point is whether an object it has detected is a bird or a plane. This decision can only be made by the system if it knows what correlates with an image of a bird and what correlates with an image of a plane. How well the system can make these decisions depends on what correlations it knows of.
Given a set of plane and bird images, machine learning can find the best correlations for the task.
However, it does not clearly state what correlations it has found.
This is something data scientists have to analyze and find out if the correlations are actually useful for the task or just an oversight of the training data.
In the end, a robust machine learning system is the result of a long discussion about your own data.
Here is a glimpse of reality:
Data Scientist: "Hey, I have images of birds and planes here. Can you find me the best correlations for it?"
Machine: "Sure, here you go, bud!"
Data scientist: "Wait, you said all pictures with blue backgrounds are planes..."
Machine: "Yes?"
Data scientist: "But why?"
Machine: "All images of planes have a blue background."
Data scientist: "Really? Oh sorry. OK, I have new images of birds and planes. Can you find me the best correlations for that?"
Machine: "Sure. Oh wow, that was a lot more difficult. Here you go, bud!"
Data Scientist: "Machine... why is a swan a plane?"
Machine: "Well, it is white, and all pictures of planes..."
Data Scientist: "Never mind, I'll be right back."
In the world of Artificial Intelligence and Machine Learning, it's crucial to grasp that machines operate based on data and lack human understanding and causality.
So handcrafted features do have their uses, and in certain situations, such as testing, where reproducibility and predictability are extremely important, it is worth questioning whether machine learning can actually solve the problem on its own or whether it makes sense to consider a handcrafted feature.
Nevertheless, AI and Machine Learning can still be incredibly valuable for automating complex tasks and uncovering patterns within vast datasets.
Think of these machines as data detectives. They sift through enormous amounts of information, identifying patterns and connections that might elude us humans. Consider them super-analysts of data.
Understanding how they find these patterns is helpful. The more we comprehend this process, the smarter we can use this technology across various fields, from healthcare to finance. It's about recognizing both the possibilities and limitations of Machine Learning and harnessing them wisely.


