
Testing is often presented as a success story. More automation. Faster feedback. Better tools. From the outside, it looks like steady progress. Inside many enterprise teams, the picture is far more mixed.
The software testing trends shaping 2026 are not all positive, even if they are widely promoted as such. Tests run more often, but confidence is harder to defend. Automation expands, yet verification shrinks. Costs increase in new and unexpected ways. And responsibility for quality becomes harder to pin down.
This article does not aim to follow the status quo. Much of what is currently celebrated in testing sounds good in theory, but breaks down in practice. Shortcuts are normalized. Trade-offs are downplayed. And familiar problems return under new names.
Instead of repeating optimistic narratives, we take a closer look at the software testing trends enterprises are already dealing with. What is quietly failing. What is being overlooked. And why not everything labeled as progress actually moves quality forward.
Because testing should create confidence, not just activity. And if something looks good on paper but fails in reality, it deserves to be questioned.
Short summary
- Automation is increasing faster than verification, leading to more test activity but less confidence in results.
- Single-prompt and happy-path testing do not scale in enterprise environments and create blind spots instead of coverage.
- Generative execution and consumption-based pricing introduce hidden costs, unstable behavior, and growing maintenance effort.
- Many current testing promises repeat past automation cycles, where speed was prioritized and quality suffered as a result.
- Testing only creates value when it is deliberate and verifiable, with clear ownership, predictable behavior, and human judgment at the core.
Trend 1: Single-Prompt Testing Is Broken by Design
One of the most visible software testing trends today is single-prompt testing. The idea is straightforward: give an AI model one prompt, generate tests, execute them, and assume coverage.
While this approach may work for small experiments or demos, it quickly breaks down in enterprise environments.
Enterprise software testing is not a one-off activity. It is a continuous effort embedded throughout the software development lifecycle, spanning APIs, user flows, integrations, data dependencies, and infrastructure.
A single prompt cannot represent this complexity, nor can it adapt to ongoing changes in the development process.
A recurring issue with single-prompt testing is the absence of real verification. Tests may run, but results are not meaningfully validated. Execution is mistaken for correctness. This creates a false sense of confidence and leads to what is effectively automation without testing. The system performs actions, but no one checks whether the outcomes meet expectations.
This problem becomes more obvious when single-prompt testing starts to resemble robotic process automation.
Steps are triggered, workflows move forward, and outputs are produced. However, there is no assertion layer, no comparison against expected behavior, and no understanding of whether the system behaves correctly under different conditions. The testing process becomes superficial.
From a practical standpoint, single-prompt testing often produces shallow test cases and brittle test scripts.
These tests may pass once, then fail when APIs change, UI elements move, or data structures evolve. Instead of improving testing efficiency, teams spend more time fixing broken tests and re-running checks that offer little insight into software quality.
There is also a cost dimension that is often overlooked. AI-driven testing frequently relies on token-based pricing models.
As prompts multiply across environments and releases, costs become difficult to predict. What initially appears to be a fast and inexpensive solution turns into an ongoing expense, without delivering comprehensive test coverage or reliable results.
Most importantly, single-prompt testing lacks context. AI-generated tests do not understand business risk, critical workflows, or regulatory requirements. Without structured test creation, relevant test data, and human oversight, these tests cannot support effective software testing or help teams deliver high-quality software.
Single-prompt testing does not redefine how testing should be done. It highlights the gap between fast AI-generated output and the rigor required in enterprise environments. As testing trends continue to evolve, this approach serves as a clear example of why automation alone is not enough.
Trend 2: Testing Is Starting to Look Like RPA
Another noticeable shift in current software testing trends is how testing increasingly resembles robotic process automation. In many teams, the focus has moved almost entirely to automating flows, while verification quietly fades into the background.
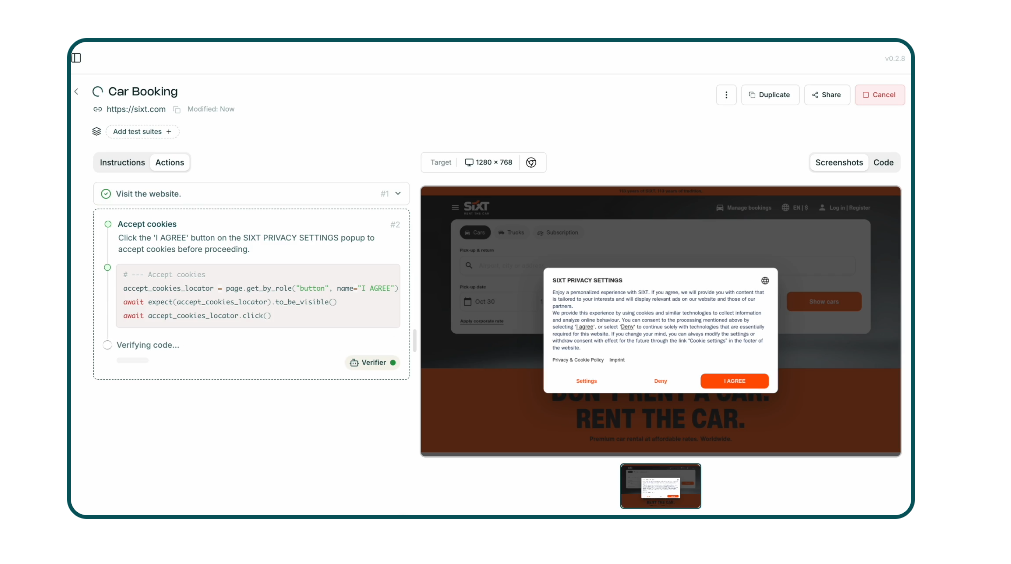
The pattern is familiar. A user journey is automated from start to finish. Login works. A form is submitted. A confirmation page appears. The test passes. Everyone is satisfied because the happy path runs without errors. But very little is actually being checked.
This is where software testing starts to lose its purpose. Executing a flow is not the same as validating behavior. Many automated tests today confirm that something happened, not that it happened correctly.
Data is rarely validated. Edge cases are skipped. Error handling is ignored. The testing process becomes about movement, not meaning.
In enterprise environments, this often happens under time pressure. Teams want fast feedback. Automation is introduced to reduce manual work and speed up releases. Over time, test automation turns into a set of scripted actions that look impressive in demos but reveal very little about real system health.
What’s missing is verification. Proper test cases include checks that confirm values, states, and outcomes. They challenge assumptions. They fail when something is wrong. When testing is reduced to happy-path automation, failures disappear from view until they reach production.
This approach also weakens software quality across the software development lifecycle. Systems change constantly. APIs evolve. Dependencies shift.
When tests only confirm that a flow still runs, regressions slip through unnoticed. Teams end up shipping features that technically work, but behave incorrectly under real-world conditions.
Another issue is how this style of testing scales. As applications grow, happy-path automation does not provide comprehensive test coverage. It creates the illusion of safety while leaving critical areas untested. Instead of supporting continuous quality, testing becomes a box to tick before release.
This is not a tooling problem. Most testing tools are perfectly capable of deeper checks. The issue is how testing efforts are framed. When success is defined as “the automation ran,” verification becomes optional. Over time, this erodes trust in test results and increases reliance on manual checks late in the development lifecycle.
Treating testing like RPA also puts pressure on already stretched teams. With insufficient testing resources, automation is expected to replace thinking. Reviews are skipped. Negative scenarios are postponed. Human oversight fades, even though it is essential for effective software testing.
As testing trends continue to evolve, this shift toward automation without verification is one of the most concerning patterns. Automation should support testing, not replace it. Without real checks, testing becomes activity without insight, and enterprises pay the price later.
Trend 3: Generative AI in Test Execution Creates a Maintenance Trap
Generative AI is increasingly being introduced directly into test execution. Instead of using predefined logic or stable assertions, teams rely on large language models to interpret results, generate steps on the fly, or decide whether a test should pass or fail. At first glance, this looks like progress. In reality, it introduces a new kind of maintenance problem.
In traditional software testing, stability is intentional. Tests are expected to behave consistently across runs, environments, and releases. When test automation depends on a generative model during execution, that stability disappears. The behavior of a test is no longer defined solely by the test case, but by the current state of the model behind it.
This raises a fundamental question: what happens when the foundation model changes?
Model updates happen regularly. Outputs shift. Interpretation changes. What passed yesterday may fail tomorrow, even if the system under test has not changed at all. In enterprise environments, this creates noise instead of clarity. Teams start investigating failures that are not caused by the application, but by a moving execution layer.
From a software development perspective, this is difficult to manage. Testing becomes coupled to something outside the software development life cycle. Releases, audits, and validations rely on results that are no longer fully reproducible. Over time, trust in automated testing erodes.
This problem becomes even more visible when testing AI-generated code. If both the code and the execution logic are influenced by generative models, it becomes hard to determine where a failure originates. Is the issue in the application? The test logic? Or the model’s interpretation at runtime?
Instead of reducing effort, this approach often increases it. Teams spend time re-running tests, comparing outputs, and explaining inconsistencies. The promise of reduced repetitive tasks is replaced by manual analysis and growing uncertainty. Maintenance costs rise, not because tests change, but because the execution logic does.
There is also a quality impact. Generative execution tends to prioritize flexibility over rigor. Assertions become vague. Checks become interpretive. This undermines rigorous testing and weakens quality assurance, especially in environments that require traceability, predictability, and high-quality software.
None of this means generative approaches have no place in testing. Used carefully, they can support test generation or help explore scenarios in the initial stages. The issue arises when generative models are placed directly in the execution path, where consistency matters most.
As software testing trends continue to evolve, this is one of the most overlooked risks. Test execution needs to be boring. Predictable. Repeatable. When execution depends on changing models, teams trade short-term speed for long-term instability.
Generative AI may accelerate activity, but without clear boundaries, it turns test execution into a maintenance trap that is hard to escape.
Trend 4: They Will Make You Pay
One of the quieter but most impactful software testing trends is how testing costs are starting to shift. Instead of being tied to tooling licenses, environments, or team capacity, costs are increasingly linked to consumption. Tokens. Executions. Model calls. Usage-based pricing that grows quietly in the background.
On paper, this looks flexible. Teams pay for what they use. In reality, it introduces a new kind of uncertainty into software testing.
In traditional setups, testing costs are relatively predictable. You budget for testing tools, infrastructure, and people. You know what it costs to run test automation, maintain test suites, and support releases across the software development life cycle. When pricing is tied to execution tokens, that predictability disappears.
Every test run becomes a cost decision.
As organizations increase automation, especially across environments and pipelines, execution volume grows fast. Reruns. Retries. Parallel jobs. Regression cycles. What used to be a technical choice now has a direct financial impact. This changes how teams think about automated testing, often in uncomfortable ways.
There is a real risk that cost pressure starts shaping testing strategies. Teams may reduce coverage to save money. Tests might be skipped, shortened, or delayed. In extreme cases, failures are ignored because rerunning tests is “too expensive.” This directly undermines comprehensive test coverage and puts continuous quality at risk.
The problem becomes even more visible when testing depends on dynamic execution logic. If outcomes vary and tests need to be re-run frequently to gain confidence, costs grow without delivering clearer answers. What looks cheap per execution becomes expensive at scale, especially in large enterprise software development environments.
Another concern is transparency. Token-based models make it harder to explain testing costs internally. Finance teams want clarity. Engineering teams want autonomy. When testing expenses fluctuate based on usage rather than intent, budgeting turns into guesswork. This creates friction between testing, development, and it operations.
Cost-driven testing also affects behavior earlier in the development process. Teams may delay integrating testing or limit it to later stages to control spend. This works against efforts to improve quality early and makes it harder to deliver high-quality software consistently.
None of this means usage-based pricing is inherently bad. It can offer flexibility and lower barriers to entry. The risk lies in tying core testing activities directly to consumption without guardrails. When execution costs drive decisions, quality becomes negotiable.
As software testing trends continue to evolve, pricing models will shape behavior as much as technology does. The question is no longer just how tests are executed, but whether teams can afford to execute them as often and as rigorously as they should.
And when cost starts dictating confidence, testing stops doing its job.
Trend 5: Promises Will Start to Be Broken (Fully Visible by 2027)
This is not a new pattern. In fact, it is one we have already discussed in previous articles throughout 2025. What is changing now is not the promise itself, but how close the industry is to realizing that it cannot be kept.
The promises around AI in testing today closely mirror the promises made about automation fifteen years ago. Faster releases. Less manual work. Higher quality with fewer people. Back then, test automation was supposed to solve scale, speed, and reliability all at once. Instead, many teams discovered that automation introduced new complexity, new maintenance work, and new gaps in understanding.
The same cycle is repeating.
Across the software testing industry, AI is presented as a way to simplify everything. Tests are generated automatically. Results are interpreted automatically. Decisions are made automatically. But as we already outlined in 2025, these promises depend heavily on ideal conditions that rarely exist in real-world software development.
In practice, teams still need strong testing practices, clear ownership, and well-defined test cases. Automation did not remove that responsibility before, and artificial intelligence will not remove it now. When expectations are set too high, disappointment is inevitable.
What changes by 2027 is visibility.
As systems grow more complex and AI-driven behavior becomes harder to reason about, cracks start to show. Testing AI-generated code requires more effort than expected. Results are harder to explain. Failures are harder to trace. Confidence becomes harder to justify. The promised productivity gains are offset by investigation, coordination, and manual verification.
This is where history repeats itself most clearly. Automation once promised to replace careful testing. Instead, it forced teams to mature their standard testing practices and rethink how quality is achieved. AI is now pushing the industry toward the same realization.
The issue is not that these technologies offer no value. They do. Used carefully, they can support automation tools, reduce repetitive tasks, and improve focus. The problem is the narrative that they can replace thinking, judgment, and accountability.
As we have already seen in the trends in 2025, expectations are moving faster than reality. By 2027, the gap will be impossible to ignore. Promises will be quietly adjusted. Marketing language will soften. Responsibility will shift back to teams.
What emerges on the other side is not the end of automation or AI, but a more realistic understanding of what they can and cannot do. One that does not try to redefine software testing, but accepts that quality still requires intent, structure, and human decision-making.
History does not repeat itself exactly. But in testing, it rhymes closely enough to recognize the pattern.
Trend 6: AI Is the New Instagram. You Are Not the Product Anymore, Your Data Is
A new narrative has quietly taken hold across the software testing industry: if the AI tool you are using today is not perfect, that’s fine. Tomorrow’s version will be better. The model will improve. Accuracy will increase. Results will stabilize.
The uncomfortable truth is that this statement is technically correct, and deeply misleading.
Yes, today’s model is the worst version you will ever use. That is true for almost any evolving technology. But what often goes unsaid is why it improves. It gets better because of usage. Because of inputs. Because of data. And in testing environments, that data comes directly from teams, systems, and real applications.
In other words, you are no longer just using the tool. You are feeding it.
As ai tools become embedded in software testing, they observe everything: test cases, failures, retries, execution paths, logs, and decisions. This is especially true when testing AI-generated code or testing AI, where feedback loops are constant. Over time, this creates highly valuable datasets derived from real enterprise systems.
This shift introduces serious quality considerations. Testing data often includes internal logic, system behavior, API structures, and edge cases that were never meant to leave the organization. In some cases, it may also involve sensitive data, configuration patterns, or indirect exposure to security-relevant behavior.
The problem is not improvement. The problem is transparency.
Teams are told that models will get better automatically, but rarely how that improvement is achieved, what data is retained, or how it is reused. In environments where data security and compliance matter, this creates risk. The more testing relies on external intelligence, the harder it becomes to draw clear boundaries.
There is also a behavioral shift. When tools promise continuous improvement, teams accept imperfect results today in exchange for future gains. Failures are tolerated. Inconsistencies are explained away. Over time, this normalizes lower standards in the present, even as expectations are pushed into the future.
This dynamic is not unique. It mirrors what happened on social platforms years ago. The service looked free. The experience improved. But the real value was created through user behavior and data. AI-driven testing is moving in the same direction.
None of this means teams should stop using emerging technologies. But it does mean assumptions need to change. Improvement is not free. Progress is not neutral. And when models learn from real-world testing activity, organizations must be clear about what they are giving in return.
As software testing trends continue to evolve, this is one of the least discussed shifts. The tooling may feel helpful, even impressive. But the long-term value exchange deserves scrutiny.
Because in this new model, you are not just testing software.
You are training the future systems that will test it.
Frequently Asked Questions
Why are software testing trends in 2026 causing more uncertainty instead of more confidence?
Many software testing trend predictions prioritize speed and automation over verification. In enterprise software testing, test automation is often used to reduce repetitive tasks, but verification does not scale at the same pace.
This leads to gaps in comprehensive test coverage, unclear results, and testing outcomes that are harder to trust.
Teams run more tests but gain less confidence in their software delivery.
How should teams approach shift-left testing without sacrificing quality?
To implement shift left testing effectively, teams need more than earlier unit testing. Strong software testing also requires early API testing, security testing, and accessibility testing, not just faster execution.
Without this balance, issues are pushed downstream instead of prevented. The most successful shift-left testing approaches focus on meaningful checks and clear ownership, not just moving tests earlier in the pipeline.
What should teams focus on instead of chasing every new testing trend?
Rather than following every new idea labeled as one of the top software testing trends, teams should focus on fundamentals. Clear test automation goals, readable results, detailed test reports, and comprehensive coverage matter more than tooling hype.
As already seen in the trends in 2025, long-term quality comes from disciplined software testing, not from adopting every new approach as soon as it appears.
Conclusion
The software testing trends shaping 2026 make one thing clear: more automation does not automatically mean better testing. When verification fades, costs rise, and responsibility becomes unclear, testing stops being a source of confidence and starts becoming a liability.
What breaks most often is not tooling, but intent. Tests run, pipelines move, dashboards turn green, yet teams still struggle to explain results, trust outcomes, or defend quality decisions. As history has shown before, shortcuts may feel efficient in the moment, but they surface later as maintenance work, production issues, and lost confidence.
If testing is meant to support real software quality, it needs structure, clear checks, and shared ownership. That’s exactly why we created our test automation cheatsheet. It’s designed to help teams step back, assess what they are actually verifying, and identify where gaps are forming before they turn into problems.


